NOMOCRAT: New Open Maltese OCR Annotated Text
- marctanti
- 3 hours ago
- 10 min read
A corpus is a large collection of text that is used for studying how language is used (for example word frequencies) and for training computers to generate text. Lots of different sources of text are used such as books, PDFs, news articles, websites, and blogs, but ideally the digital plain text should be readily available so that a corpus of searchable digital text would be easy to compile.
For the Maltese language, the largest public corpus is the MLRS Korpus Malti which is an opportunistic corpus consisting of text collected from the web and some books (copyrighted material is not made publicly available). However, there is a problem in that a lot of text is extracted from PDFs by simply extracting the digital text available within it. This leads to certain problems.
Problems with PDFs
PDFs are not designed to have the text they contain be extracted into a corpus. PDFs are designed to be read by humans and to be printed. Although text can be copied from them, there will generally be the following problems:
Interruptions in the main text
One obvious problem is that paragraphs of text tend to be interrupted by unrelated text in the form of figure captions, footnotes, headers/footers/page numbers, and so on. The below example shows this:

Din ir-riċerka saret bħala parti mill-proġett
‘Nippromwovu l-inklużjoni soċjali ta’ persuni
b’diżabilità b’imġiba diffiċli ħafna’ (ESF3.105),
kofinanzjat mill-Fond Soċjali Ewropew (FSE). Dan
il-proġett għandu l-għan li jipprovdi taħriġ lillistaff tal-organizzazzjonijiet li jaħdmu mal-persuni
b’diżabilità b’imġiba diffiċli ħafna. Fi tmiem it-taħriġ,
1 Traduzzjoni minn E. Emerson’s (1995) Challenging behaviour:
analysis and intervention with people with learning
difficulties (Cambridge University Press)
l-istaff se jkun jista’ jħarreġ membri oħra tal-istaff florganizzazzjonijiet rispettivi tagħhom. Ir-riżultati ta’
din ir-riċerka huma maħsuba li jdawlu t-termini ta’
referenza tas-sejħa għall-offerti għat-taħriġ imsemmiThe last paragraph in the first column is interrupted by a footnote. A computer analysing the this paragraph will be led to believe that the footnote is a continuation of this paragraph.
Merged columns
Depending the way the PDF was constructed or how the text was entered in the word processing application, columns of text could be treated as a single column with spaces in between. Below is an example showing how the two columns should be treated as two vertical paragraphs but are treated as two lines instead.

Jørgen Greve Cor J. W. Meijer
Chairman DirectorFont-based character substitutions
A particularly insidious problem with early Maltese digital texts is that people did not have access to proper Maltese diacritics ('ċ', 'ġ', 'ħ', and 'ż') because Unicode wasn't widely available or access was not widely known about yet. For those that did not want to use non-diacritical versions of the characters, the most common solution was to use fonts that would make other characters appear as Maltese diacritics, for example '\' would appear as 'ż'. To this day, people still refer to typing with Maltese diacritics as "fonts Maltin" (Maltese fonts).
Fonts can make any character appear as any other character, but underneath the apparent 'ż' there is still the original '\', and this '\' is what gets copied when the text is extracted from the PDF, as shown below:

Li©i dwar
Opportunitajiet Indaqs
G˙all-Persuni b’DiΩabilità
2000The publisher of this PDF decided to use the less used characters '©', '˙', and 'Ω' to appear as 'ġ', 'ħ', and 'ż'. These underlying characters are what ends up in the corpus.
Ligatures
Ligatures are a typographic feature that replaces characters that are next to each other with a single character that takes less space, to make the text presentation nicer. Below is an example from Wikipedia:

That single character replacement ends up in the underlying text, and will be included in the corpus. Below is an example:

Ar=ficialCopying this word, for some reason, ended up with a '=' replacing the 'ti' ligature.
A solution
Hopefully these problems together with other problems such as words getting hyphenated and ending up being inserted into the corpus as two pieces and PDFs that consist of scanned pages with no searchable text should convince you that extracting clean text from PDFs is a challenge. But what if the underlying text is completely ignored and only the apparent text is used? What if the text can be copied in the same way that a human would copy the text, visually.
The NOMOCRAT project, an 18 month project funded by the Research Excellence Programme by Xjenza Malta, is about creating a pipeline for extracting text from PDFs using computer vision techniques, namely:
Document Layout Analysis (DLA) - Automatically recognising the different parts of a page.
Optical Character Recognition (OCR) - Automatically recognising the text in an image.
The idea being that the different parts of the page, such as tables, titles, footnotes, and so on are first identified using a DLA as shown below:

...and then the parts that are not of interest (for example the headers and footers) are filtered out and the text in what is left is copied visually using an OCR (taking care to keep captions and footnotes separate from the main text).
The first challenge was to create a data set of these tasks to be able to evaluate existing DLAs and OCRs on Maltese documents.
The data set
A collection of Maltese language PDFs (and Word documents) on the web were collected from a number of websites such as the Maltese government website, L-aċċent (a magazine on the Maltese language), and others. The pages in the documents were then extracted as images. This results in 346 documents from 5 websites and 7,311 pages. A sample of these pages needed to be extracted for manual annotation.
The sample needs to be balanced, so the page images were turned into dense feature vectors using the multimodal transformer Donut's penultimate layer. These feature vectors were then clustered into two clusters (determined by siluette score) using a k-means algorithm and a random 100 pages from each cluster was selected. The thumbnails of the first few pages from each cluster can be seen below:
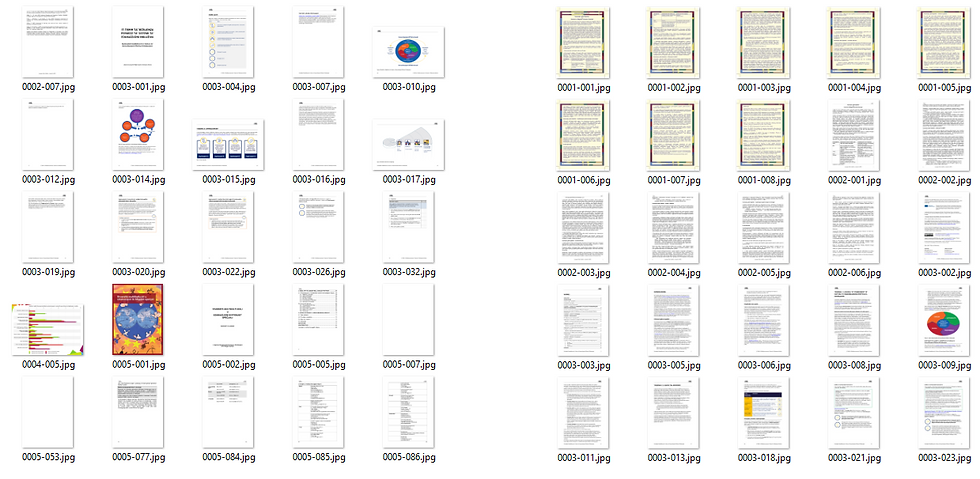
It seems like the cluster on the left consists of pages with small amounts of text and the cluster on the right has large amounts of text.
For the DLA, an additional 66 pages that contained footnotes, captions, and tables were selected from a second sample of 200 in order to have a better representation of these labels.
Following this, two research support assistants used Label Studio to annotate the pages. For OCR annotations, every paragraph in the page (including page numbers and other fragments) was marked with a bounding box and the text in the bounding box was automatically transcribed using the Tesseract OCR for English (Label Studio provided instructions for using an existing docker container for English Tesseract but not for other languages), followed by a manual correction. For DLA annotations, polygon regions were used to mark page regions using the label set defined in DocLayNet.
This resulted in a data set of 200 annotated pages for both DLA and OCR annotations and 66 additional annotated pages for DLA. Unfortunately, the amount of mistakes found in the annotations was unacceptable, and the majority of the project time ended up being spent on fixing the mistakes. In the end, a sample of 57 pages that were confirmed to be correct by the project coordinator were extracted as a final, verified data set that can be used for the OCR and 84 pages were confirmed for the DLA. The OCR transcriptions consist of both line-by-line transcriptions as presented in the PDF and paragraph transcriptions where lines were joined together manually (and hyphenated words joined back together).
Evaluating pre-trained models
We started by evaluating off-the-shelf pre-trained models on our data set in order to see which model was best for Maltese text. Two research support officers were hired, one for each task.
DLA benchmark
We used the YOLO family of models that were trained on DocLayNet on the entire 84 DLA annotated pages to extract the following pixel-level accuracies:
YOLO model | Accuracy (%) |
12s | 0.8409 |
12m | 0.8374 |
11l | 0.8356 |
11n | 0.8322 |
11s | 0.8306 |
11m | 0.8299 |
12l | 0.8293 |
12n | 0.8256 |
All YOLO models perform very similarly. Below is an example of a correctly segmented page using 12l:

OCR benchmark
We evaluated 3 different downloadable OCR models (not online services), but only Tesseract supported Maltese. We are interested in evaluating how well we can generate transcriptions that are paragraphs rather than a list of lines of text because that is what is necessary for a corpus. 2 of the OCRs generate such transcriptions directly, but Tesseract generates lines, so we developed a line joining algorithm that attempts to reproduce the original paragraph from a list of lines, including fixing hyphenations. This algorithm was found to correctly join 181 multi-line paragraphs out of 183 in the OCR data set.
The OCR data set was split into a development set and test set and measured the character error rate (fraction of character omissions, insertions, and substitutions in the generated text) on the test set.
Model | CER (lower is better) |
Tesseract + line joiner | 0.033 |
Donut | 0.53 |
TrOCR | 0.689 |
Tesseract is by far the best of the models. Below is an example of a very badly transcribed image:

Fil-kotba li nittraduċi jien dejjem nipprova nikteb introduzzj emm tematika ki Dan għax nemm raduzzjoni jmur raduzzjoni nnifsu. daklli qed jittraduċi raduttiv. Dan l-għ it minnu mal-qarrej kemm biex jiggwid, jgħinu ji diskussi Uħud mi it-Trans oħra u hem eża dik it-traduzzjoni għandi diversi kitbiet dwar it-traduzzjoni kemm i er Kreat xi ftit lura. Diskussji għajnuna reċiproka l-avviċinament tagħi hom lejn ukolldwar il-proċessta en li l-involviment tat-il hinn minn sempliċi it-traduttur jeħtieġlu i kemm fil-livell temati arfien imbagħad ikun Fin) aj a X'kienet tinvolvi mill-a partikolari. Fuq live -teoriji u l-proċessi ta iv fit-Traduzzjoni bi għal dawk li jipparteċipaw fiha biex fe en un ki jjeb hu aki li fi n tt lingwis traduzzjoni. innhom dehru f'Aspetti tat-Traduzzjo l-Malti, edit) u ppubblikat minn Charles Briffa, oħraj 'rivisti bħas-Sumposia Melitensia U Il-Ma Lokalment id-diskussjoni dwar il-proċess tat-traduzzjoni għadha joni kostruttiva hi importanti u tista' oni traduzzjoni. raduttur fit-l-att tat-onxju ta' ukoll dak lijaqsam anki biex iku ademiku ihom jiġu ni Maltija: at 'xi kotba ti, tkun ta' jissaħħaħ kif għandhom jittraduċuAs a corpus extraction pipeline
Finally we wanted to see how well putting the best DLA and the best OCR together into a pipeline to extract corpus text from a page would perform. We followed this procedure:
Use the DLA to extract labelled bounding boxes from the page.
Filter out boxes with the following labels: Picture, Formula, Page Header, Page Footer, Table. Tables were left out because they would require further processing to identify the cells which we did not readily have access to.
Group the remaining bounding boxes into 'channels' of independent text:
The Text channel consists of the labels Text, Section-header, List-item, and Title.
The Caption channel consists of the Caption label.
The Footnote channel consists of the Footnote label.
An algorithm was developed to determine a reading order to each bounding box. This was done by detecting columns based on the width of the bounding box relative to the page, and then going down each column.
The OCR is applied on each bounding box.
The transcriptions are ordered by the channel first (texts followed by captions followed by footnotes) and each channel is ordered by reading order.
To evaluate this, we manually extracted a reading order data set from the OCR data set by putting all the paragraphs of a valid type (according to step 2 above) into a list in the order we would expect. As a baseline, we also extracted the selectable text from each PDF page in the OCR data. This is to be able to compare how well the pipeline we developed performs compared to just extracting the text in the traditional way. We used the Python package PyPDF to extract text from the target pages of a PDF. To be fair, we left out all the pages containing tables since we decided to completely avoid tables in order to avoid inflating the number of errors.
Below are the results of applying character error rate on the extracted linear page text compared to the manually determined text:
Method | CER |
YOLO 12l + Tesseract + line joiner | 0.1057 |
PyPDF (baseline) | 0.484 |
A significant improvement, but a character error rate of 10% is still too much for practical use.
Fine-tuning models to perform better
The next step was to fine-tune the OCR and DLA models to perform better. Unfortunately there was no time to also apply them on the pipeline.
OCR fine-tuning
Fine-tuning Tesseract on the development set of the OCR data set resulted in a CER of 0.034, which is worse than the 0.033 obtained with the base model. This was thought to be due to the size, so instead we focused on generating synthetic data. The idea is to use the MLRS Korpus Malti to extract paragraphs from there and turn them into images with different fonts and word wrapping widths. We would then train Tesseract to predict the original paragraph from the image. We extracted 32,000 paragraphs and used a modified version of the OCR Data Toolkit to generate the images. We noticed the Tesseract suffers the most on paragraphs with coloured backgrounds, so we added some coloured backgrounds to the synthetic data set. This resulted in a slightly improved CER on the test set of 0.031.
DLA fine-tuning
A synthetic data set for the DLA is less straight-forward than for the OCR, but thankfully there was no need for it. The DLA data set was split into train and test sets and the polygons were converted into bounding boxes by using the smallest rectangle that contains a polygon. YOLOv26 was used for fine-tuning, and the evaluation was performed using intersection-over-union, a common measure used for evaluating segmentations. The original intersection-over-union on the test set without fine-tuning was 0.5952 while after fine-tuning was 0.9762, which is an exciting improvement for such little effort!
Outcomes
From this project, our main contribution will be our data sets. The annotated data will be available using a permissive license and the collected documents will be available in another data set called dokumenti.mt.
We are also hosting a competition at DocEng26 where we are taking the paragraphs extracted from the OCR data and inviting participants to develop a better synthetic data set than ours to create an even better OCR. For this reason, the full data set will only be made public after the competition ends in July in order to avoid leaking the test set used in the competition.
Finally, the line joining algorithm we developed will be included in the Maltese text processing Python package malti.
Follow us on our project page for updates!
Future work
This all preliminary work that is planned to be expanded into a full corpus building project. The experience gained from making the data sets is going to be used on an application that we recently came across that is specifically designed for OCR-based text extraction called eScriptorium, although its intended use is for digitising historical documents rather than modern PDFs. We hope to release a large and clean corpus for Maltese in the near future.
Credits
This project was funded by Xjenza Malta, project number REP-2024-057. The following are the people who worked on this project:
Marc Tanti as principle investigator, Institute of Linguistics and Language Technology, University of Malta
Alexandra Bonnici as co-investigator, Department of Systems & Control Engineering, Faculty of Engineering
Stefania Cristina as co-investigator, Department of Systems & Control Engineering, Faculty of Engineering
Emma Fenech as Research Support Officer
Vanya Gelfo as Research Support Officer
Jamie Buttigieg as Research Support Assistant
Isabelle Camilleri as Research Support Assistant



Comments